
A data blog about where people are spending their money.
Interesting insights about how people are ‘talking’ with their dollars.
And about what can you learn by looking into transaction data?
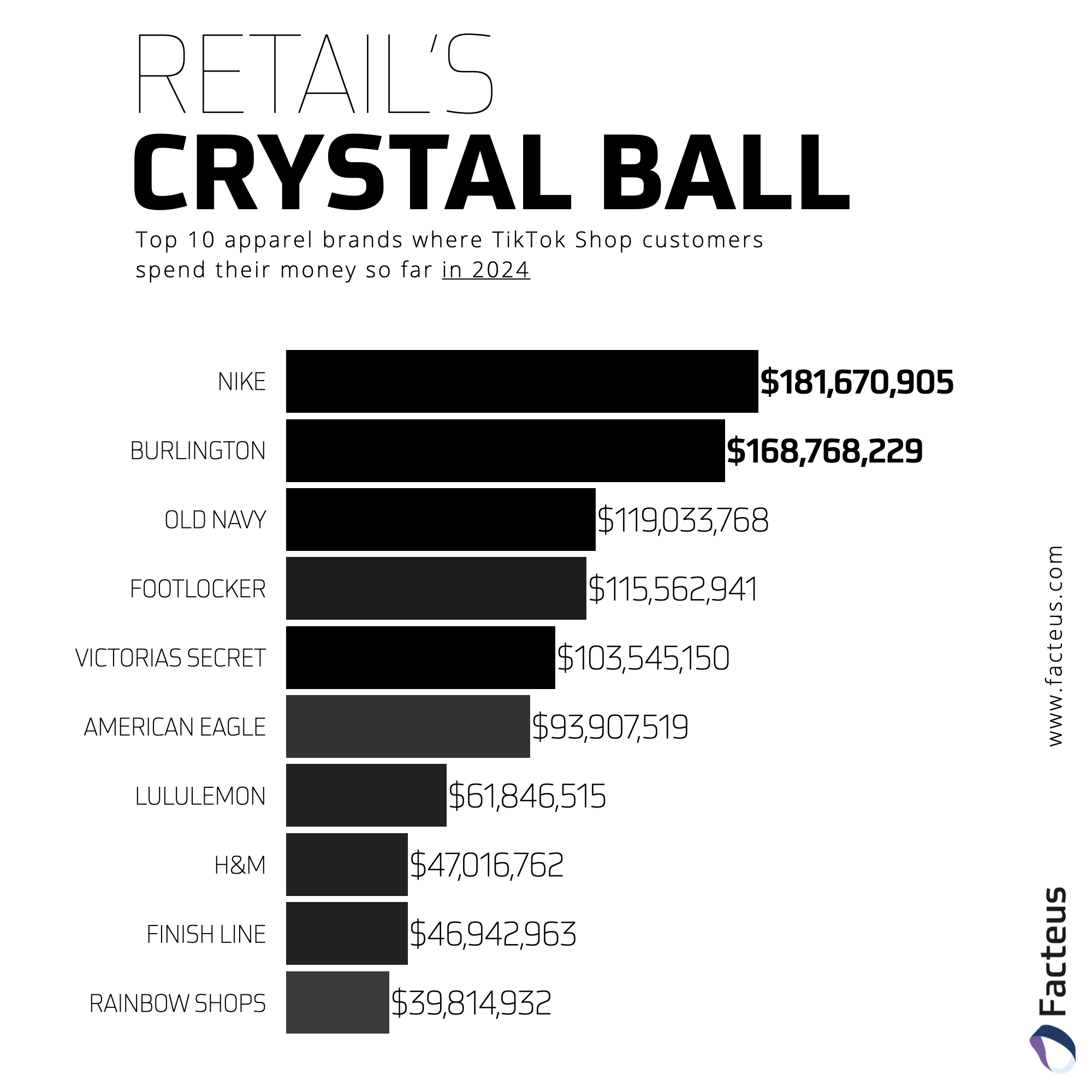
Top 10 Apparel Brands on TikTok Shop in 2024
Discover which clothing & apparel brands are dominating TikTok Shop sales so far in 2024, according to the latest transaction data.

The Mind-Reading Retailer: Harnessing Consumer Transaction Data
Retailers often wonder about the whispers of wallets and what each swipe of a card means. Facteus offers a lens into this otherwise invisible space, giving retailers better eyes on the full spectrum of a customer's shopping journey.

2023 Black Friday Shopping & Spending Data Unpacked
Facteus Black Friday Spend Tracker reveals eye-opening insights about holiday shopping, where consumers spent more over 2023 Black Friday, and so much more.
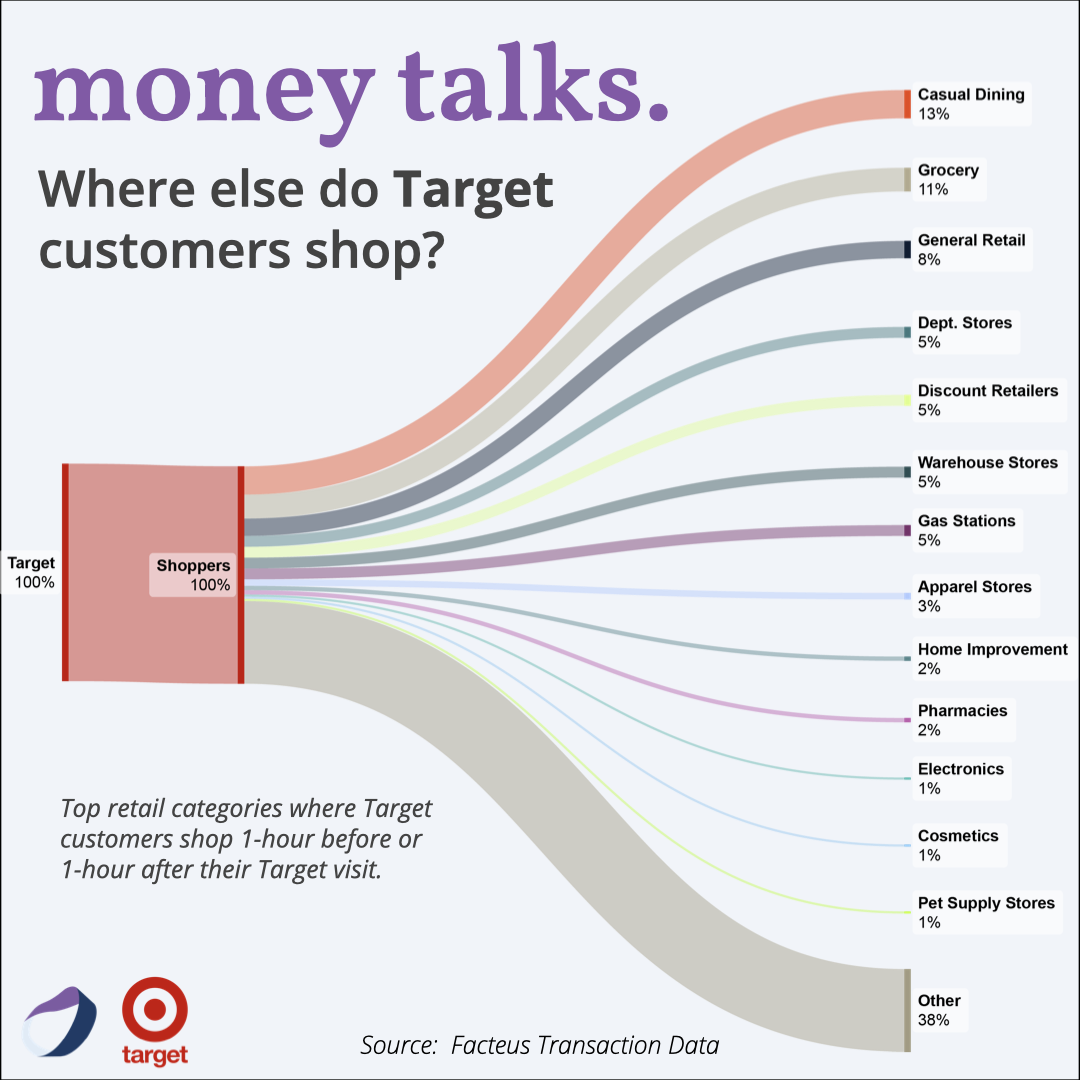
Where Else Do Target Customers Shop?
Discover where customers spend money before & after they shop at Target in this insightful infographic featuring retail alt data & consumer spending data associated with Target shoppers.
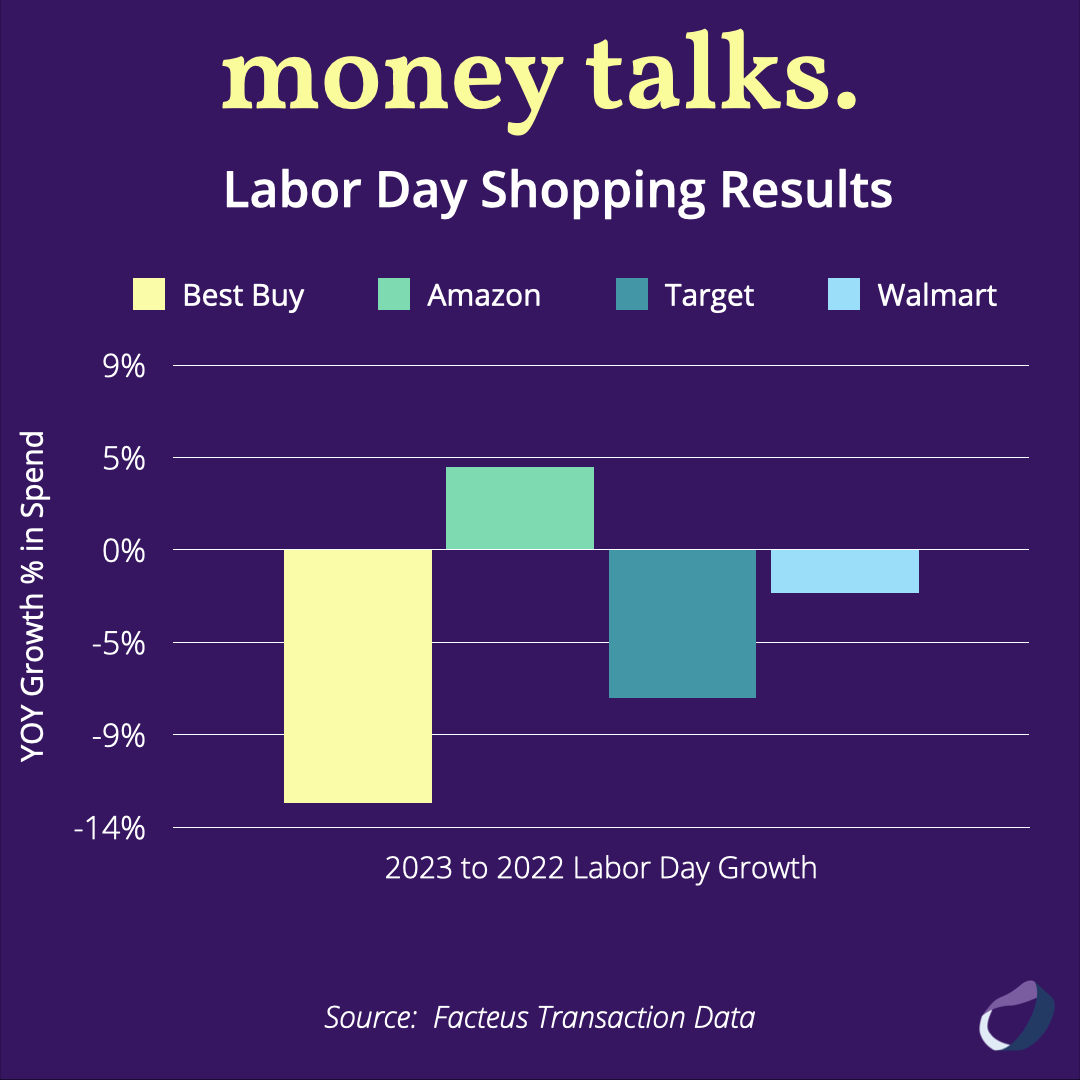
The Curious Case of Labor Day 2023: Facteus Data Confirms Early Predictions
Did predictions about shrinking consumer spending come true with the 2023 Labor Day shopping holiday? Facteus Ultra shares answers by analyzing the latest transaction data.

Data-Enhanced Insights into Chipotle vs. Panera Bread with Mobius and ChatGPT
If you're a decision-maker in the QSR industry, or just passionate about the potential of AI, you won't want to miss this read. Discover how Mobius can inform strategies, shed light on average ticket sizes, regional preferences, generational spending habits, and more!
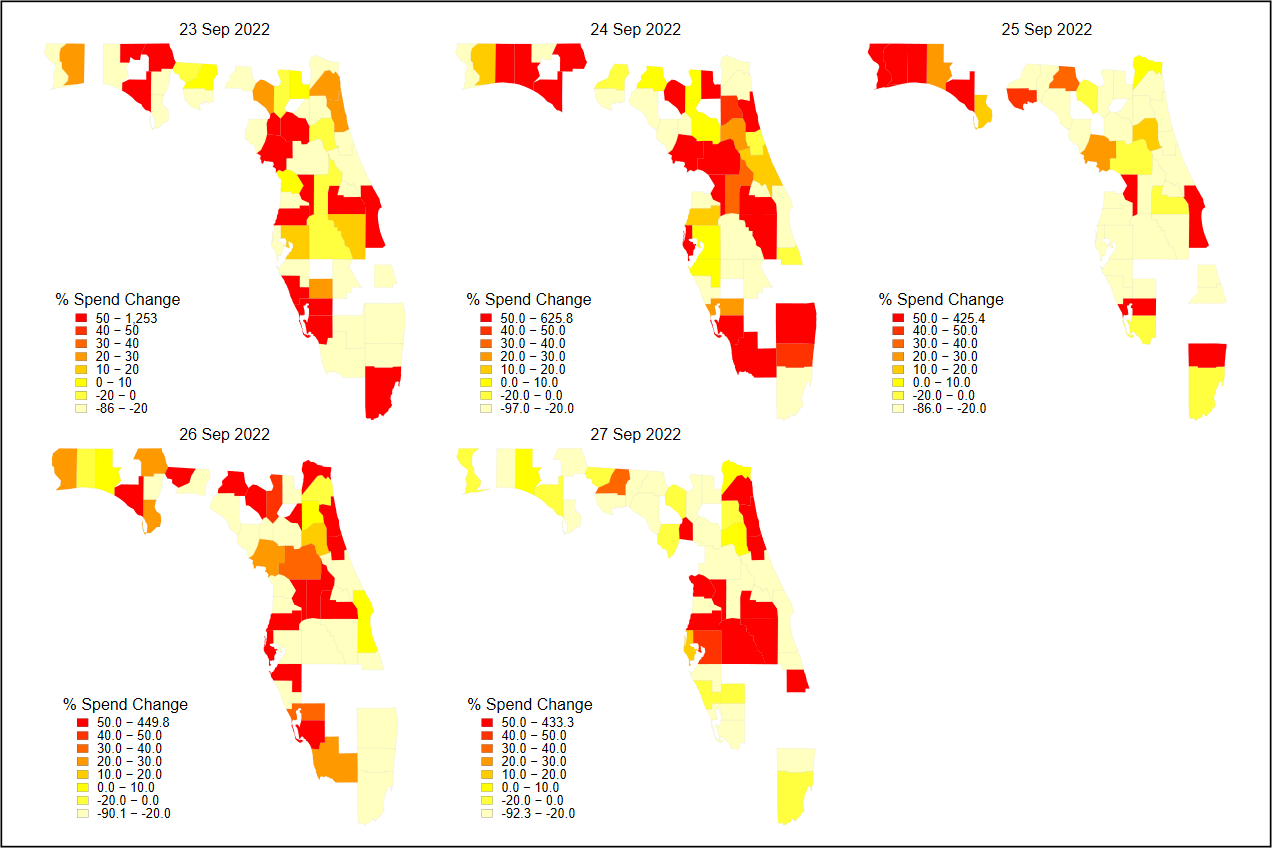
Hurricanes and Consumers: The Power of Granularity in Understanding Consumer Behavior
Discover how consumer card spending behavior shifted around Hurricane Ian & why this weather event was one of the costliest natural disasters in 2022, according to alt data insights.

ChatGPT and Mobius in Tandem: Harnessing the Power of Real-Time Consumer Data and AI
Discover the transformative potential of OpenAI's ChatGPT enhanced with Facteus' comprehensive consumer spending data to create our data-enhanced AI, Mobius.

Unveiling Consumer Spending Habits: Exploring the Rise of Grocery Delivery Services Through Transaction Data
Transactional data can be instrumental in detecting and understanding new trends, especially in grocery delivery services.

Leveraging Transaction Data for Competitive Benchmarking in Retail
Competitive benchmarking enables retailers to compare their performance, strategies, and practices with industry peers or best-in-class companies. Here’s how.

Transaction Data for Share of Wallet Analysis: Empowering Retailers to Know Their Customers Better and Boost Business Performance
Here’s how transaction data can be used for share-of-wallet analysis, with concrete examples of how businesses can benefit from this valuable information.

Leveraging Transaction Data for In-Depth Trade Area Analysis: Uncovering Consumer Spending Patterns
Transaction data can elevate trade area analysis, giving retailers a better understanding of a customer base. That can inform decisions regarding store locations, product selections & marketing approaches.

Unlock the Potential of Retail Industry Insights with Consumer Credit and Debit Card Transaction Data
Discover the distinct advantages of using consumer transaction data, with real-world examples of how businesses leverage this information to achieve growth.

Harness the Power of Consumer Transaction Data: Analyzing Cross-Shopping Behaviors for Business Success
Dive into the concept of cross-shopping, its significance & how Facteus can help businesses uncover valuable insights from consumer spending data & credit card spending data.
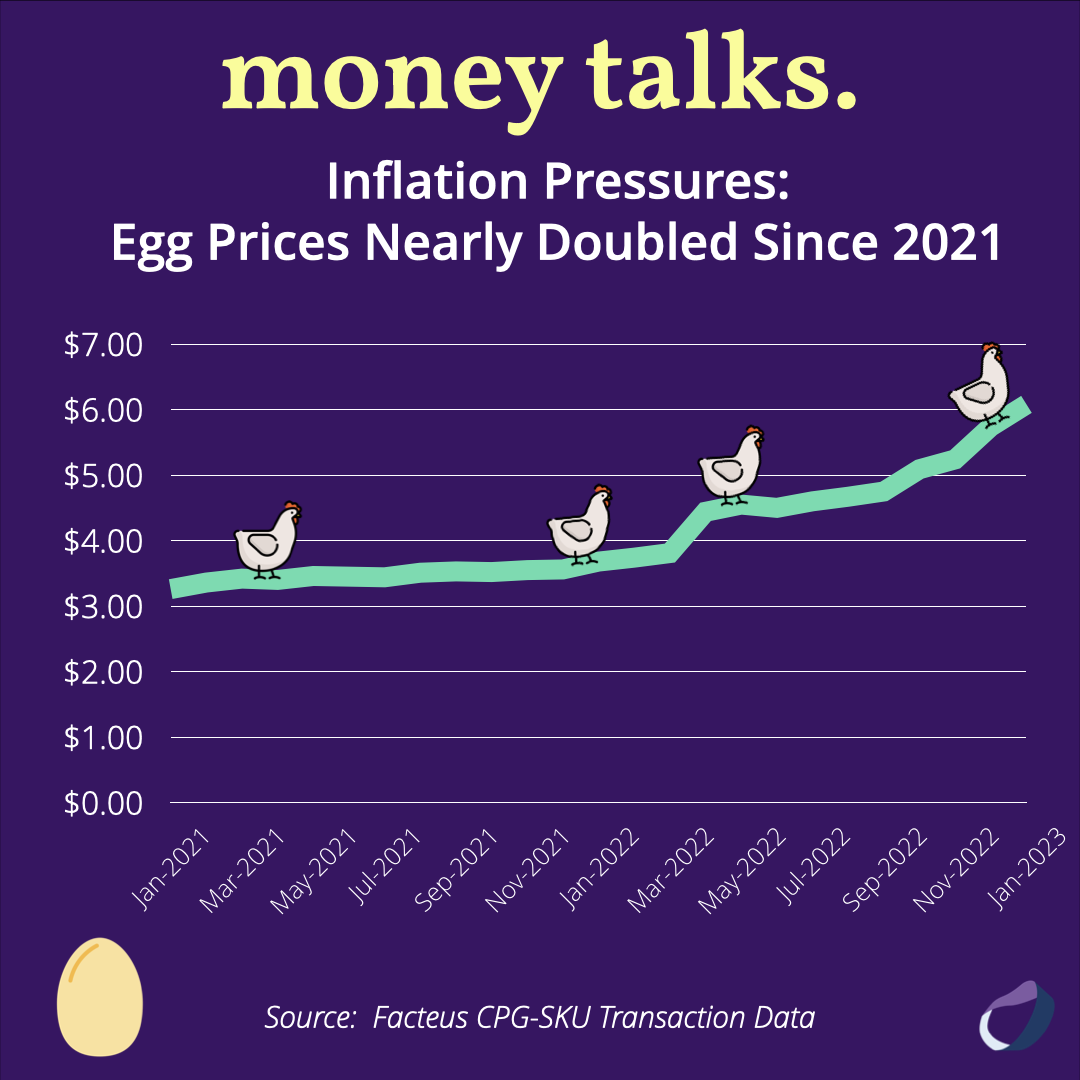
Inflation Pressures: Egg Prices Nearly Doubled Since 2021
Inflation pressures have inflamed prices, doubling the cost of eggs since 2021. Here’s what those price changes look like & what that could mean for the future.

Home DIYers Cross Shopping Brand Loyalty
Home DIYers & pros still prefer Home Depot as their top choice for materials and supplies, according to the latest credit card & sales transaction data. Guess who comes in second? It’s NOT Lowe’s.

Millennial Cross Shopping Coffee Preferences
Starbucks is still the king of coffee for Millennials, according to consumer data. Here’s a look at their coffee preferences, based on transaction data.
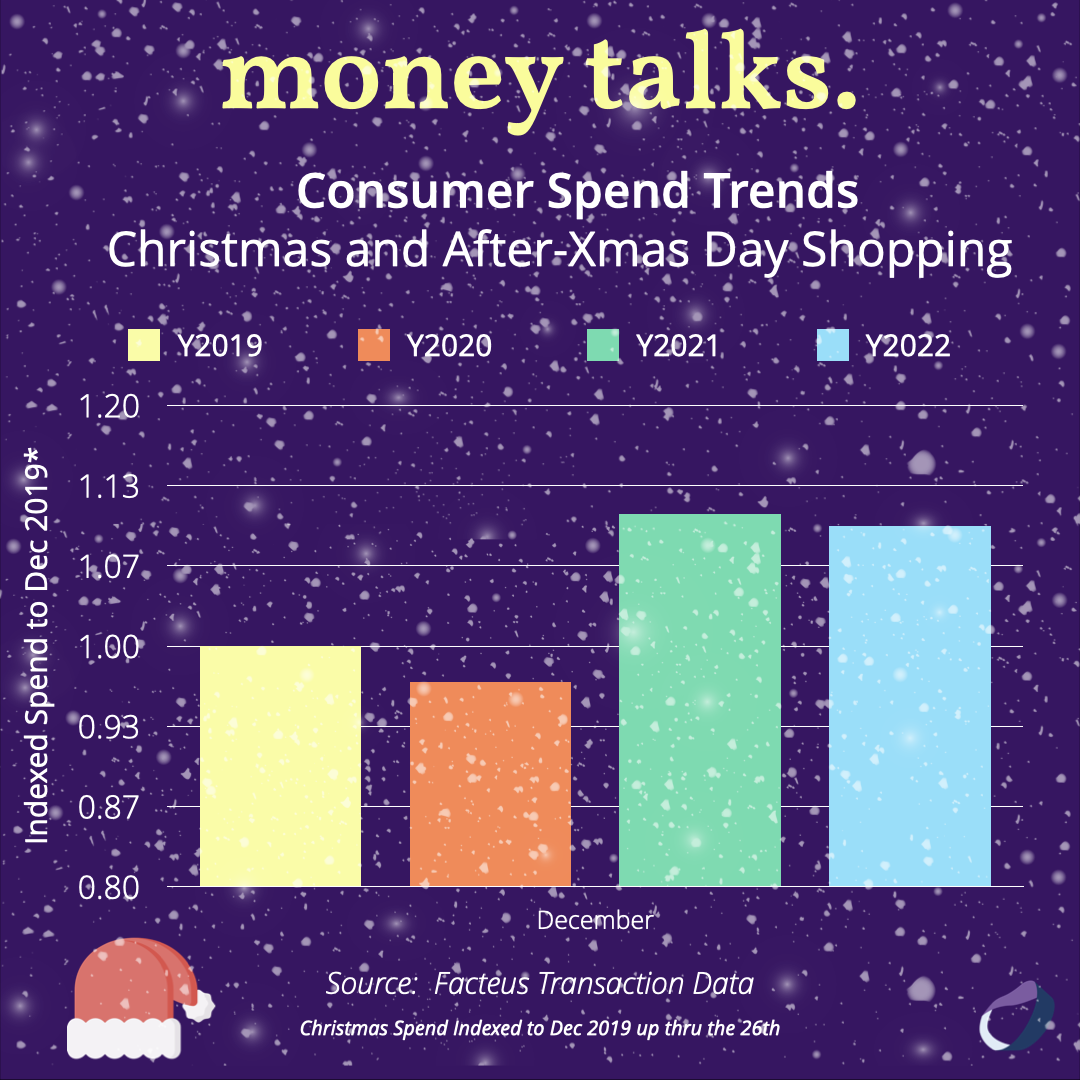
Consumer Spend Trends - Christmas Shopping
Consumer spending was STRONG over the 2021 holiday season, the latest transaction data reveals. Here’s why & what the data revealed.
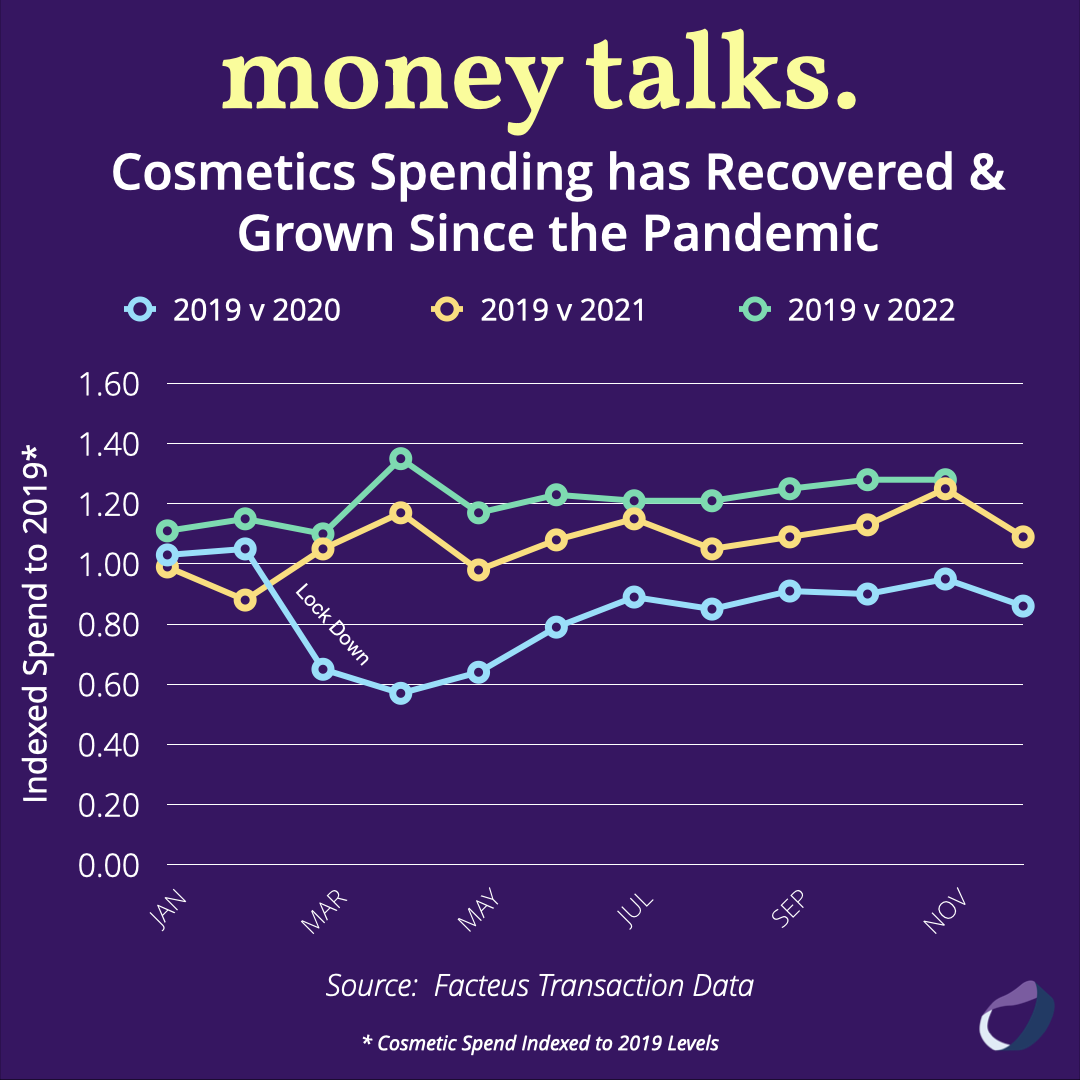
Cosmetic Spending Has Recovered & Grown Since the Pandemic
Cosmetic spending has bounced back & surged above pre-pandemic levels, customer spending data shows. Here’s what that could mean for the future.

Walmart Black Friday Spend Trend Results
Walmart's Black Friday 2022 spend level was slightly up from 2021, sales transaction data reveals. Does that mean Walmart will be a go-to retailer for holiday shopping? Find out now.